Intro
The World’s Most Advanced Open Source Relational Database
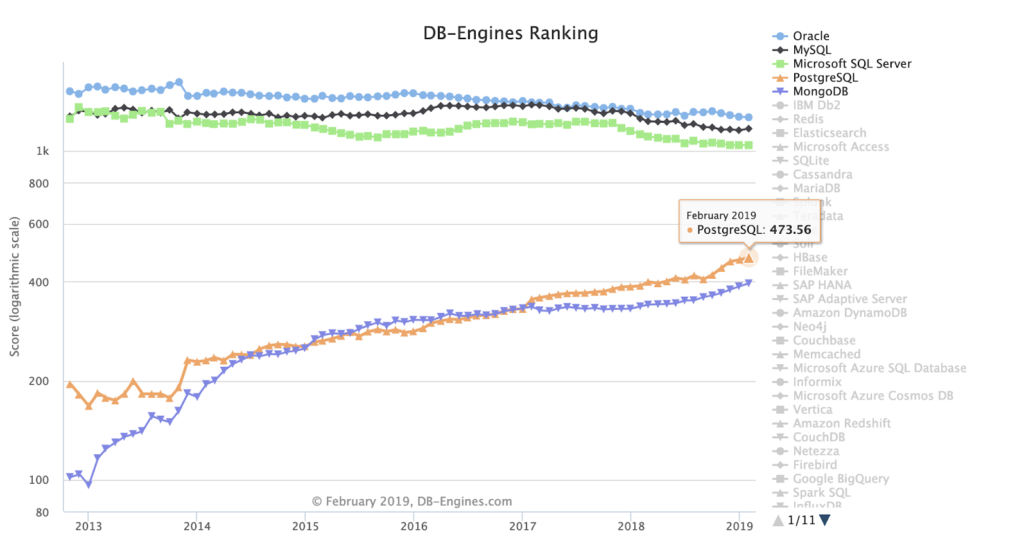
PostgreSQL is winning this title for the second year in a row. First released in 1989, PostgreSQL turns 30 this year and is at the peak of its popularity, showing no signs of ageing with a very active community. It’s the fastest growing DBMS last three years.
Everyone wants a fast database, I think that is what everybody can agree upon. The question is: fast in what respect?
In terms of databases, there are at least different directions of fast:
- number of transactions per second
- throughput or amount of data processed
These are interrelated but definitely not the same.
And both have completely different requirements in terms of IO. In
general, you want to avoid IO at all cost. This is because IO is always
slow in comparison to access to data in memory, CPU-caches of different
levels or even CPU registers. As a rule of thumb, every layer slows down
access by about 1:1000.
For a system with high demand for a large number of transactions per
second, you need as many concurrent IOs as you can get, for a system
with high throughput you need an IO subsystem which can deliver as many
bytes per seconds as possible.
That leads to the requirement to have as much data as possible near to the CPU, e.g. in RAM. At least the working set should fit, which is the set of data that is needed to give answers in an acceptable amount of time.
Each database engine has a specific memory layout and handles different memory areas for different purposes.
To recap: we need to avoid IO and we need to size the memory layout so that the database is able to work efficiently (and I assume that all other tasks in terms of proper schema design are done).
Here are the critical parameters
- max_connections
This is what you think: the maximum number of current connections. If you reach the limit you will not be able to connect to the server anymore. Every connection occupies resources, the number should not be set too high. If you have long run sessions, you probably need to use a higher number as if the sessions are mostly short-lived. Keep aligned with configuration for connection pooling. - max_prepared_transactions
When you use prepared transactions you should set this parameter at least equal to the amount of max_connections, so that every connection can have at least one prepared transaction. You should consult the documentation for your prefered ORM to see if there are special hints on this. - shared_buffers
This is the main memory configuration parameter, PostgreSQL uses that for memory buffers. As a rule of thumb, you should set this parameter to 25% of the physical RAM. The operating system itself caches as much data to and from disk, so increasing this value over a certain amount will give you no benefit. - effective_cache_size
The available OS memory should equal shared_buffers + effective_cache_size. So when you have 16 GB RAM and you set shared_buffers to 25% thereof (4 GB) then effective_cache_size should be set to 12 GB. - maintenance_work_mem
The amount of this memory setting is used for maintenance tasks like VACUUM or CREATE INDEX. A good first estimate is 25% of shared_buffers. - wal_buffers
This translates roughly to the amount of uncommitted or dirty data inside the caches. If you set this to -1, then PostgreSQL takes 1/32 of shared_buffers for this. In other words: when you do so and you have shared_buffers = 32 GB, then you might have up to 1G of unwritten data to the WAL (=transaction) log. - work_mem
All complex sorts benefit from this, so it should not be too low. Setting it too high can have a negative impact: a query with 4 tables in a merge join occupies 4xwork_mem. You could start with ~ 1% of shared_buffers or at least 8 MB. For a data warehouse, I’d suggest starting with much larger values. - max_worker_processes
Set this to the number of CPUs you want to share for PostgreSQL exclusively. This is the number of background processes the database engine can use. - max_parallel_workers_per_gather
The maximum workers a Gather or GatherMerge node can use (see documentation about details), should be set equal to max_worker_processes. - max_parallel_workers
Maximum parallel worker processes for parallel queries. Same as for max_worker_processes.
The following settings have direct impact on the query optimizer, which tries its best to find the right strategy to answer a query as fast as possible.
- effective_io_concurrency
The number of real concurrent IO operations supported by the IO subsystem. As a starting point: with plain HDD try 2, with SSDs go for 200 and if you have a potent SAN you can start with 300. - random_page_cost
This factor basically tells the PostgreSQL query planner how much more (or less) expensive it is to access a random page than to do sequential access.
In times of SSDs or potent SANs this does not seem so relevant, but it was in times of traditional hard disk drives. For SSDs an SANs, start with 1.1, for plain old disks set it to 4. - min_ and max_wal_size
These settings set size boundaries on the transaction log of PostgreSQL. Basically this is the amount of data that can be written until a checkpoint is issued which in turn syncs the in-memory data with the on-disk data.
User cases
8 GB RAM, 4 virtual CPU cores, SSD storage, Data Warehouse:
- large sequential IOs, due to ETL processes
- large result sets
- complex joins with many tables
- many long lasting connections
So let’s look at some example configuration:
max_connections = 100 shared_buffers = 2GB effective_cache_size = 6GB maintenance_work_mem = 1GB wal_buffers = 16MB random_page_cost = 1.1 effective_io_concurrency = 200 work_mem = 64MB min_wal_size = 4GB max_wal_size = 8GB max_worker_processes = 4 max_parallel_workers_per_gather = 2 max_parallel_workers = 4
2 GB RAM, 2 virtual CPU, SAN-like storage, a blog-engine like WordPress
- few connection
- simple queries
- tiny result sets
- low transaction frequency
max_connections = 20 shared_buffers = 512MB effective_cache_size = 1536MB maintenance_work_mem = 128MB wal_buffers = 16MB random_page_cost = 1.1 effective_io_concurrency = 300 work_mem = 26214kB min_wal_size = 16MB max_wal_size = 64MB max_worker_processes = 2 max_parallel_workers_per_gather = 1 max_parallel_workers = 2
Rasperry Pi, 4 arm cores, SD-card storage, some self-written Python thingy
max_connections = 10 shared_buffers = 128MB effective_cache_size = 384MB maintenance_work_mem = 32MB wal_buffers = 3932kB random_page_cost = 10 # really slow IO, really slow effective_io_concurrency = 1 work_mem = 3276kB max_worker_processes = 4 max_parallel_workers_per_gather = 2 max_parallel_workers = 4